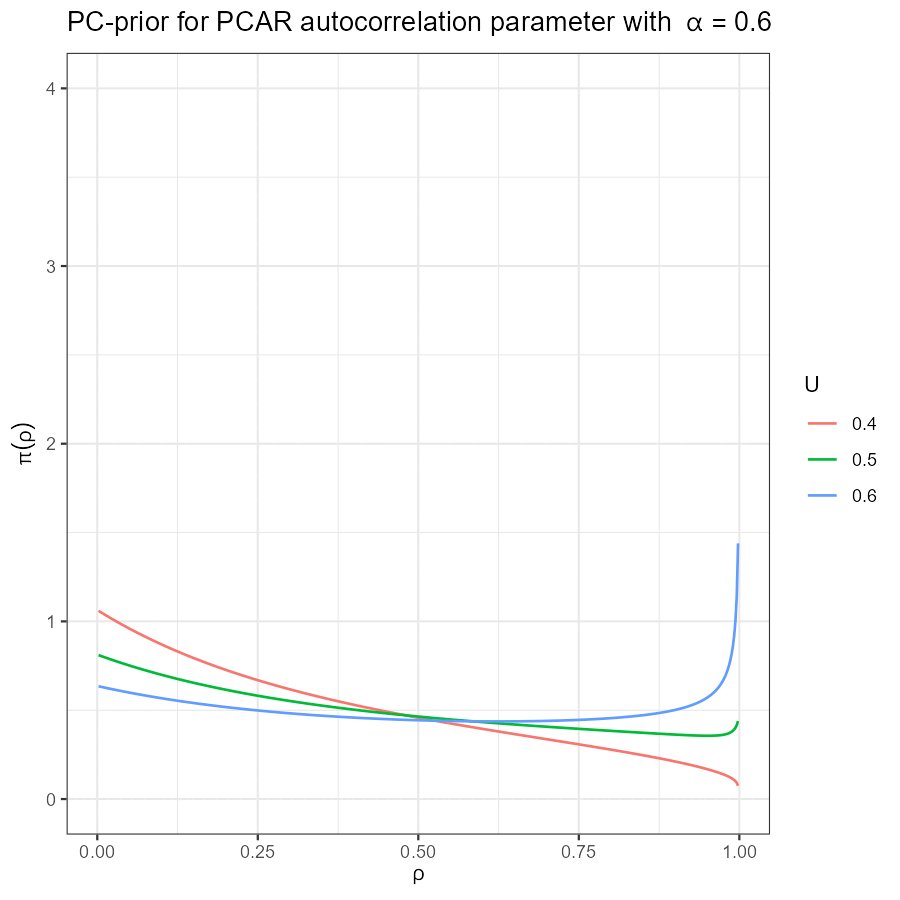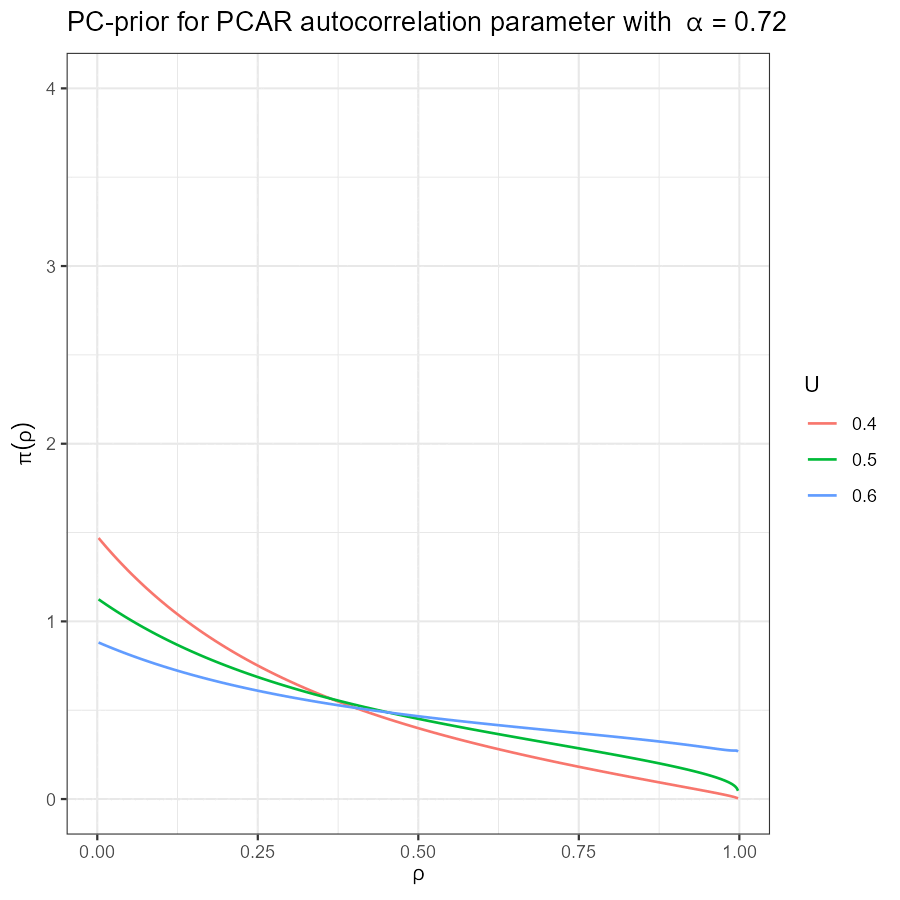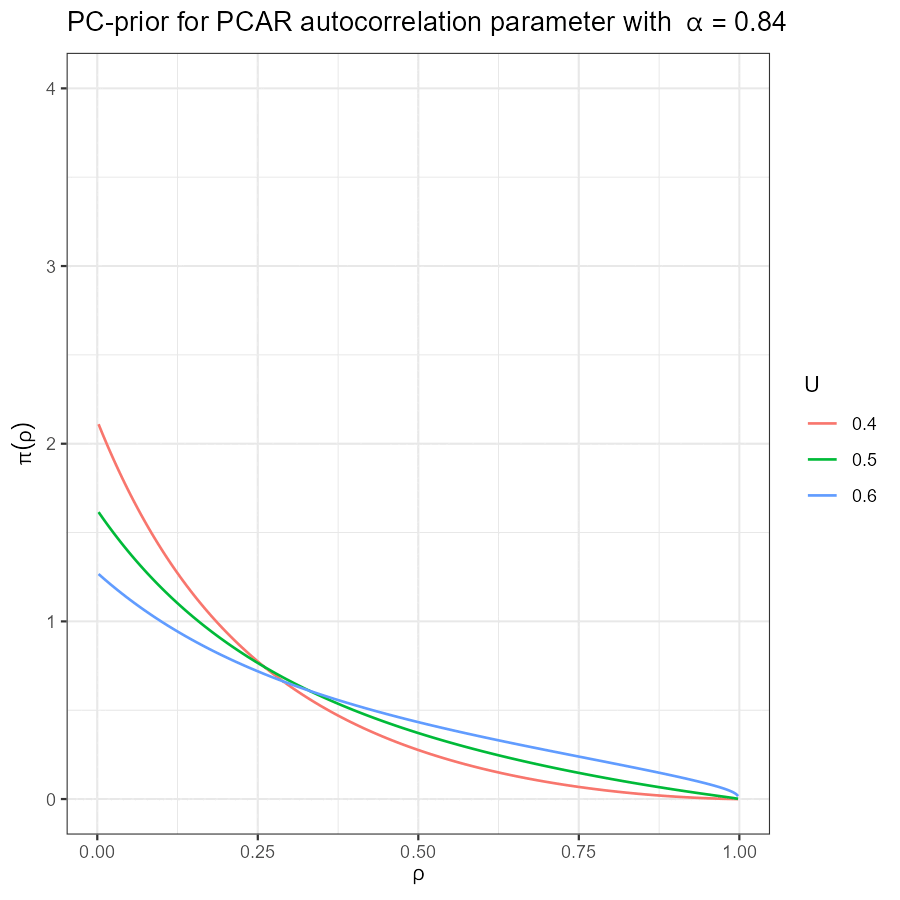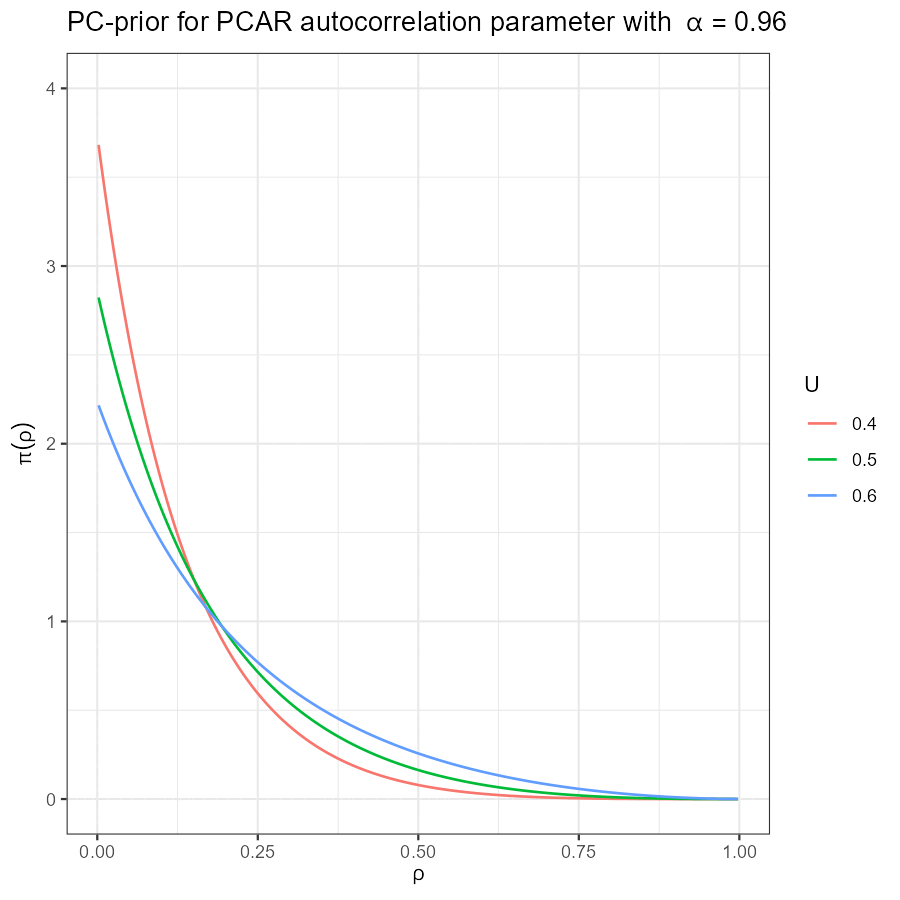
Battagliese, Diego. 2020.
“Extensions of the Univariate PC Prior.” Annali Del Dipartimento Di Metodi e Modelli Per l’Economia, Il Territorio e La Finanza (MEMOTEF), 33–46. https://doi.org/https://doi.org/10.13133/2611-6634/509.
Besag, Julian, Jeremy York, and Annie Mollié. 1991.
“Bayesian Image Restoration, with Two Applications in Spatial Statistics.” Annals of the Institute of Statistical Mathematics 43 (1): 1–20.
Botella-Rocamora, Paloma, Miguel A Martinez-Beneito, and Sudipto Banerjee. 2015.
“A Unifying Modeling Framework for Highly Multivariate Disease Mapping.” Statistics in Medicine 34 (9): 1548–59.
Freni-Sterrantino, Anna, Denis Rustand, Janet van Niekerk, Elias Teixeira Krainski, and Håvard Rue. 2025.
“A Graphical Framework for Interpretable Correlation Matrix Models for Multivariate Regression: A. Freni-Sterrantino Et Al.” Statistical Methods & Applications, 1–39.
Gelfand, A. E., and P. Vounatsou. 2003.
“Proper Multivariate Conditional Autoregressive Models for Spatial Data Analysis.” Biostatistics 4 (1): 11–15. https://doi.org/https://doi.org/10.1093/biostatistics/4.1.11.
Gelman, Andrew, Jessica Hwang, and Aki Vehtari. 2014.
“Understanding Predictive Information Criteria for Bayesian Models.” Statistics and Computing 24 (6): 997–1016. https://doi.org/10.1007/S11222-013-9416-2.
Leroux, Brian G., Xingye Lei, and Norman Breslow. 2000.
“Estimation of Disease Rates in Small Areas: A New Mixed Model for Spatial Dependence.” In Statistical Models in Epidemiology, the Environment, and Clinical Trials, edited by M. Elizabeth Halloran and Donald Berry, 179–91. New York, NY: Springer New York. https://doi.org/https://doi.org/10.1007/978-1-4612-1284-3_4.
Polettini, Silvia, Serena Arima, and Sara Martino. 2024.
“An Investigation of Models for Under-Reporting in the Analysis of Violence Against Women in Italy.” Social Indicators Research 175 (3): 1007–26.
Riebler, Andrea, Sigrunn H Sørbye, Daniel Simpson, and Håvard Rue. 2016.
“An Intuitive Bayesian Spatial Model for Disease Mapping That Accounts for Scaling.” Statistical Methods in Medical Research 25 (4): 1145–65.
Rue, Haavard, Sara Martino, and Nicholas Chopin. 2009.
“Approximate Bayesian Inference for Latent Gaussian Models by Using Integrated Nested Laplace Approximations.” Journal of the Royal Statistical Society Series B: (Methodological) 71 (2): 319–92. https://doi.org/10.1111/j.1467-9868.2008.00700.x.
Simpson, Daniel, Haavard Rue, Andrea Riebler, Thiago G. Martins, and Sigrunn H. Sørbye. 2017.
“Penalising Model Component Complexity: A Principled, Practical Approach to Constructing Priors.” Statistical Science 32 (1): 1–28. https://doi.org/10.1214/16-STS576.
Stoner, Oliver, Theo Economou, and Gabriela Drummond Marques da Silva. 2019.
“A Hierarchical Framework for Correcting Under-Reporting in Count Data.” Journal of the American Statistical Association.
Van Niekerk, Janet, Elias Krainski, Denis Rustand, and Haavard Rue. 2023.
“A New Avenue for Bayesian Inference with INLA.” Computational Statistics and Data Analysis 181. https://doi.org/10.1016/j.csda.2023.107692.